 ミント音声教育研究所
ミント音声教育研究所
ホーム ミント アプリ
ミント アプリ
ケーションズ
ホーム 映画映像シーン検索サイト
映画映像シーン検索サイト
セリーフ 字幕付き動画再生サイト
字幕付き動画再生サイト
トーキーズ ミント名作劇場
ミント名作劇場 日本の昔話
日本の昔話
朗読絵本
「竹取物語」 群馬の昔話
群馬の昔話
朗読絵本
「猿地蔵」」 日本の名作
日本の名作
朗読
芥川龍之介
「トロッコ」 英語朗読絵本
英語朗読絵本
マザーグース Mother Goose 映画
映画
オズの魔法使い
歌「オーバーザレインボー」 映画
映画
カサブランカ
シーン「君の瞳に乾杯」 英語で折り紙 Origami
英語で折り紙 Origami
折鶴 つる crane- ベクターライブラリ
 公開作品一覧
公開作品一覧- 英語作品
 朗読絵本
朗読絵本
ふしぎの国のアリス
第1巻 聞き取りドリル
聞き取りドリル
オバマ大統領 就任演説 聞き取りドリル
聞き取りドリル
オバマ ノーベル平和賞演説- 語学ソフト
 ミングル
ミングル
リーダビリティ計測ソフト ワーズピッカー
ワーズピッカー
英単語拾い2- ゲーム
 朗詠・百人一首
朗詠・百人一首
読み上げ&ゲーム 数独ナンプレゲーム
数独ナンプレゲーム
東海道五十三次
詰独 一人旅 数独ナンプレゲーム
数独ナンプレゲーム
富嶽36景 富士登山
詰独 次の一手- ユーティリティ
 書き起こしソフト
書き起こしソフト
ゆ~ゆ バリュー 書き起こしソフト
書き起こしソフト
ゆ~ゆ ライト 書き起こしソフト
書き起こしソフト
ゆ~ゆ ビジネス 書き起こしソフト
書き起こしソフト
ゆ~ゆ アカデミー
2018/10/11 分かりやすい用例文を収集 | ||||||||
|
辞書には、字義と用例がセットになっている。高校の頃使った単語カードは、トランプの半分もない紙面なのに、しっかり用例が載せてあった。 字義と文脈のセットが大事 字義は文脈で決まるのだから、当然の配慮だろう。 ミント音声教育研究所は、文脈の臨場感で語彙習得を促進しようと、Seleaf や CORPORA などの字幕付き映像対訳コーパスを提供してきた。映画やプレゼンの用例を網羅的に準備しておいて、語彙による検索結果を一覧表示する。  CORPORA へのQRコード(上)と URL
規模拡大の弊害と対策 開発時と比べてコーパスが大きくなり、1回の検索でヒットする件数も格段に増えてきた。規模の拡大はいいことばかりではない。選択肢の増大は利便性を損なうこともあるのだ。表示数が多すぎると目移りがして返って戸惑うことになる。そこで、適応学年などのフィルターで絞り込み、学習者のレベルや目的にあわせる工夫を追加してきた。  so * as を検索し、フィルターをかけたところ
チャンクとセンテンスの区別と連関 さて、Seleaf や CORPORA などの字幕付き映像対訳コーパスは、音声フレーズ(呼気段落 breath group)に注目したチャンキングを行っているので、ひとつの文(sentence)がたいてい2つ3つの字幕に分かれている。これはワーキングメモリの処理能力に合わたもので、反復練習に最適化した結果である。これは長所なのだが、意味理解の視点から見ると短所になっていた。フレーズだけでは意味が完結しにくいからだ。 チャンクとセンテンスの二重性は、言語の永遠のテーマだと思う。生活の複雑さにあわせて、文も長くなる。ワーキングメモリは長い文を一度に処理できないから、文をいくつかのチャンクに分割せざるを得なくなるわけだ。かといって、1つのチャンクで1つの文にすることは不可能ではないが、全体としての意味が取り辛くなってしまう。 | ||||||||
| ||||||||
|
今回の追加機能は、規模拡大の弊害に対処するとともに、チャンクとセンテンスの二重性がもたらす短所を補うひと工夫である。意味的に分かりやすくて、しかもワーキングメモリが受容しやすい用例だけを収集する工夫である。字幕(フレーズ)は意味の一部であることが多いので、字幕が文(sentence)となっている物だけを提供すればよいと考えた。こうすれば、映画やプレゼンの筋を知っていなくても、その文だけを見れば納得しやすいはずだ。 実例を使って説明していく。
検索対象を TED コーパスにセットして so * as を検索すると、983件ヒットする。ただし、最初は100件だけ表示される。ここでは用例を網羅したいので全部表示させることにする。
ヒット項目をすべて表示させるにはツールバーの右下にある all ボタンをタップする。少々時間が(10秒以上)かかる。 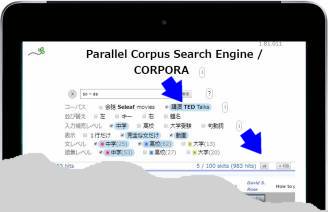
983件すべてを閲覧してもよいが、時間がないので、フィルターで機械的に絞り込む。 まず最初に 完全な文だけにチェックを入れる。このフィルターだけで46件に減らすことができる。 | ||||||||
| ||||||||
|
もっと減らしたいときは、レベルフィルターを使う。
学年が高いほど複雑な用例になりやすいことから、まず大学レベルをカットし、つぎに高校レベルをカットする。順に消しながら適当な数にトリミングできたところで、残った字幕の検討を始めればよい。 トリミングするとき文と語彙のどちらからカットすればよいか。日本の学習者は語彙に弱いことを考えると、分かりやすい用例を集めるには、語彙から消すのがよいようだ。 高校の語彙レベルを消したところで残りが16個になったのでやめる。 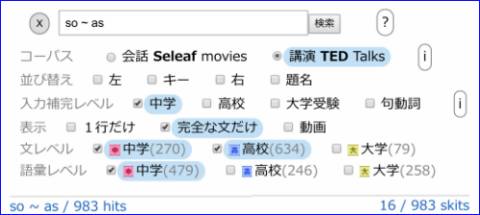 ツールバーの設定は上の図のようになっている。 残った項目は下の図のようになった。  フィルターで絞り込んだ結果(一部)
このようにフィルターを使って、学習目的と学習者のレベルに応じた分かりやすい用例を収集できるようになった。 | ||||||||
| ||||||||
|
日英対訳コーパスが、BNC など他のコーパスと大きく違う点は、音映像にある。そのことにより、音映像をベースにした字幕で区切った構造を持っている。 この違いは、思うほどに小さくはない。 日英対訳コーパスのゴールは音映像 多くのコーパスは、検索結果のテキスト一覧がゴールになっている。 これに対し日英対訳コーパス CORPORA では、テキストは、それをよりどころとして音映像を取り出す手段である。ゴールは音映像そのものなのだ。 テキストとしての字幕をタップすれば、その字幕や前後の文脈を円滑に再生することを目指して開発を進めてきた。この目的が達成されて一息入れたところで、テキストとしての利用価値を高める必要性に気づかされたのだった。 テキストとしての読みやすさを改善 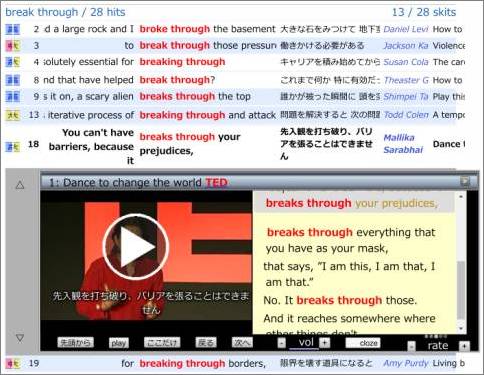 キーワードは break through、コーパスは TED Talks
上がこれまでのレイアウトで、下が改善されたもの。 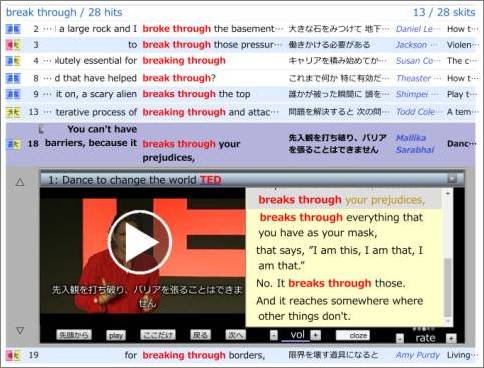 ぱっと見の印象は同じかもしれない。しかしテキストを読み始めると違いが分かってくる。 テキストの流れを整序 / 省略記号 部分を拡大して比較する。  before
 after
微妙な違いだが、読もうとするとはっきり差が見えてくる。 上の例では 通し番号の 9 につづく s it on の 先頭の s が意味不明となりやすい。これに対して下の例では s のところが ... に変わっている。文字が省略されていることを伝える記号のおかげで、it の前には文字が隠れていることがわかる仕組みだ。 テキストの流れを整序 / 全文表示 1行で表示できない部分が左右にはみ出てしまうと、せっかくの文脈が読み取れなくなってしまう。そこで、全体を見渡せるように縦に複数行に表示させた。それが下の図である。左が3行、右が2行になった。  before
左を読んでから右に移る仕組みなのだ。しかし人の習慣としては、左から右に続けて読んでしまう。多少上下に差があるがその程度は乗り越えて 左から右へ、下に下りて左から右へと目が流れてしまう。 このような誤読を起こさせないための工夫を考案した。それが下の図である。  after
左の最下行と同じ高さで右の最初の行が始まる仕組みだ。 人の直感で正しく認識できる自然なレイアウトになった。説明なくても左2行を読み終えてから右に移れるようになった。 ここまでくると左側のテキストのすぐ外にある数字 18 が邪魔になってきた。目障りなので次回の改定で、書体か配置を変えることにする。 | ||||||||
| ..[↑] 4 | ||||||||
|
2018.10.11 田淵龍二 TABUCHI, Ryuji | ||||||||