 ミント音声教育研究所
ミント音声教育研究所
ホーム ミント アプリ
ミント アプリ
ケーションズ
ホーム 映画映像シーン検索サイト
映画映像シーン検索サイト
セリーフ 字幕付き動画再生サイト
字幕付き動画再生サイト
トーキーズ ミント名作劇場
ミント名作劇場 日本の昔話
日本の昔話
朗読絵本
「竹取物語」 群馬の昔話
群馬の昔話
朗読絵本
「猿地蔵」」 日本の名作
日本の名作
朗読
芥川龍之介
「トロッコ」 英語朗読絵本
英語朗読絵本
マザーグース Mother Goose 映画
映画
オズの魔法使い
歌「オーバーザレインボー」 映画
映画
カサブランカ
シーン「君の瞳に乾杯」 英語で折り紙 Origami
英語で折り紙 Origami
折鶴 つる crane- ベクターライブラリ
 公開作品一覧
公開作品一覧- 英語作品
 朗読絵本
朗読絵本
ふしぎの国のアリス
第1巻 聞き取りドリル
聞き取りドリル
オバマ大統領 就任演説 聞き取りドリル
聞き取りドリル
オバマ ノーベル平和賞演説- 語学ソフト
 ミングル
ミングル
リーダビリティ計測ソフト ワーズピッカー
ワーズピッカー
英単語拾い2- ゲーム
 朗詠・百人一首
朗詠・百人一首
読み上げ&ゲーム 数独ナンプレゲーム
数独ナンプレゲーム
東海道五十三次
詰独 一人旅 数独ナンプレゲーム
数独ナンプレゲーム
富嶽36景 富士登山
詰独 次の一手- ユーティリティ
 書き起こしソフト
書き起こしソフト
ゆ~ゆ バリュー 書き起こしソフト
書き起こしソフト
ゆ~ゆ ライト 書き起こしソフト
書き起こしソフト
ゆ~ゆ ビジネス 書き起こしソフト
書き起こしソフト
ゆ~ゆ アカデミー
2018/09-06-07 第13回 テキストアナリティクス・シンポ | |||||||||||||||||||||||||||||||||||||||
|
言語処理学会に加入してまだ1年が経たないが、驚いたり、感心したりすることが一杯ある。そのひとつが、各種研究会のお知らせである。毎週のように研究発表を募集するメーリングリストが舞い込んでくる。 そんな中のひとつが、今回参加した 第13回 テキストアナリティクス・シンポジウム であった。 シンポジウムと銘打ってあるのでどんなスタイルだろうかと期待半分、不安半分でTEDコーパス関連研究発表を申し込んだのだが、参加してみて、このスタイルがすっかり気に入ってしまった。詳しくは後で紹介する。   近代的設備の会場は緑豊かなキャンパスに建っていた
成蹊大学(東京・吉祥寺)
 ひとつの教室に参加者全員が集まって行われた
参加者は100名程度であった
発表会場は、よく整備されていて快適だった。プロジェクタの接続は従来のRGB(15ピン)と最新のHDMIの両方が準備されていて、音声も滑らかに再生される。視聴者サイドとしては、前の方の長テーブルにコンセントが設置されていたので、パソコンやスマホの電池切れの心配がなく、発表を聞きながら、記録や情報閲覧をすることができた。 一歩会場を出るとすぐそこにはホール形式のロビーが広がり、一角に軽飲食が用意されていたので一息つくことができた。建物を出て緑の中をしばらく歩くとバス通りを車で混んでいる。コンビニや食堂が通りの両側に並び、昼食に困ることはなかった。 テキストの形態素解析・構文解析・語彙分類・機械学習を主要手段とする研究とは、一見して無縁な田淵であるが、応募要綱に「隣接分野との連携」に目を向けて「多様な参加者による議論の場」と位置づけていたことに励まされ、音声解析の側面からテキストを解析してきた経験を紹介しようと思い立った。ありがたいことに採用され、そうして実現したのが「テキスト分析と多分野との境界」をテーマとしたセクションであった。 興味深いことは、直前にアメリカで開催されたACL2018(56th Annual Meeting of the Association for Computational Linguistics)で最高論文賞に選ばれた内容が、聴解過程における脳波の研究であったことである。この話題は次の機会に譲り、本大会の開催要項とプログラムから紹介をはじめる。 | |||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||
|
日時: 2018年 9月 6日(木) ~ 7日(金) 議題: 第13回 テキストアナリティクス・シンポジウム 会場: 成蹊大学 6号館401教室 主催: 言語理解とコミュニケーション研究会(NLC) ドキュメントコミュニケーション研究会(IPSJ-DC)共催 | |||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||
|
⇒プログラム 詳しいプログラムは上のアドレスからのページに譲る。 タイムスケジュールは実に簡明で、大学の授業のように90分発表があって10分の休憩となる。午前中に1コマあり、午後に3コマとなっていた。1コマごとにテーマが決まっていて3人が発表する。一人25分ずつなので三人で75分。すると90分-75分で15分残る。この時間がシンポジウム・タイムとなるのだった。発表者3名が前に並んですわり、会場からの質疑に応答する。テーマに沿った全体的質問が主なのだが、一人の発表の終わりごとに設けられた5分の質疑応答で消化不良の質問を発表者に投げかけることもできる。 議論することで理解を深め、考えや体験を共有するにはとてもよいスタイルだった。これぞ学術的研究会だと感心させられた。 しかし、こうしたスタイルを実現するには、主催側も発表側もおおきな努力が要求される。特に主催側は大変だと思う。応募された概要を読み込み三人ずつのグループに分けてテーマをつけプログラムにまとめ上げるまでがひと仕事だし、シンポの進行役は、三人の発表をよく理解しつつ同時にテーマに沿った議事の運営を要求されるからだ。 会場から活発に質疑があれば仕切るだけかもしれないが、そうでないときに備えて、テーマに沿った適切な質問を、しかも三つの発表に絡めた形で準備しておかなければならない。 2日間で5つのテーマ・セクションがあったが、いずれも極めて専門的で、細かくは計算手法や計算順序、大きくは研究課題の設定や結果数値の評価などで、気の抜けないシンポジウムだった。 理論と手法を共有しつつ、実務を科学的に遂行する専門家集団による学術団体はさすがに違うと、肌で実感した。 | |||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||
|
6日と7日の2日間で8つのセクションがあった。
○ 印が言語分析に関わる研究発表だ。 テーマセッション以外に企画された国際会議参加報告では、言語解析に関わる世界の第一線研究者たちの動向が伝えられ、とても参考になった。 テーマセッションでは、nwjc2vec に対して word2vec の CBOW モデルを用いて各単語を 200 次元のベクトルで表現した分散表現を WMD の計算に使用した・・・と言うような表現が続き、解析結果が示されるという具合だ。素人には呪文にしか思えないので、ここからは利用者目線で研究を案内する。 | |||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||
|
ひとくちで テキストアナリティクス(文解析)と言って分かる方は少ないと思う。計算言語学(Computational Linguistics)と言った方がピンとくるかもしれない。コンピュータを使ってデジタルテキストを解析する分野である。 pepper など、最近何かと注目度が高い応答ロボットを例に取ってみよう。 以前に比べて実用レベルになってきたとは言え、天気や挨拶など日常会話で当たり障りのない会話ならある程度滑らかで、また目新しさもあるが、目指しているのは、もっと踏み込んだ会話だ。たとえば・・・ ヒト: 日清食品の株価が上がったみたいだね。 ロボット: なおみ効果かな? ヒト: 買ってみようか? ロボット: さて、どうかなぁ? ヒ: 不安材料が!? ロ: う~ん、中国市場でカップヌードルが伸び悩み始めたんだ。 ヒ: 大変だね。でも、手を打ってるんだろう? ロ: ブランド強化に乗り出してるんだって ・・・(ストーリーは架空) こんな会話ができるようになるためにはどんな情報収集が必要なのかを考えてみよう。
ヒトと滑らかに会話をするためには、個々のヒトが日々接している情報を熟知しておかなければならない。誰が話し相手になるかは不明だから、膨大な情報となる。そんな情報をあらかじめロボットに埋め込んでから販売するわけには行かない。何より、それではホットニュースに対応できない。 そこで、話題に応じてロボットが自分でウェブにアクセスし、最適なサイトを見つけてテキストを解析し、話題にあった文章にして返せるようにすればよい。これが Computational Linguistics の課題である。 今回の研究会では、上に上げたさまざまな情報パーツに挑戦する姿が浮き彫りとなった。 | |||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||
|
かつては消えてなくなっていた人々の思いや会話や体験が、今では即座にデジタル化されて共有されるに至った。Google や Facebook や FBI や NSA などは世界中の情報を蓄積しつつあると思われている。この爆発的な過剰情報過渡期に、社会の対応が急がれている。 今回参加した「第13回 テキストアナリティクス・シンポジウム」は、こうした課題に挑む専門家たちが格闘するスクリーンショットであった。旧社会を引きずりながら新社会を切り開いてきた第一人者たちと、デジタル・ネイティブとかジェネレーションZとか称される駆け出しの若者たちの熱気が、2日をかけてじっくり煮込まれ、ひとつの作品に作り上げられたように見受けられた。 ここに集まった人々は情報の発信者ではない。いや、生情報の作り手(著作者)ではないと言うのが正確だろう。彼らは、報道記者や、SNS投稿者や、意見表明する顧客や、企業広報や、さらには作家たちが日々生み出す情報に立ち向かっているのだ。彼らの立ち位置を見極めるには情報社会における「情報」の階層構造を知っておく必要があるだろう。
Twitter, Facebook, LINE, YouTube などの投稿共有ツール、報道やブログなどのニュースサイト、Yahoo!知恵袋やはてななどの質問サイトなどはオープンな(公開)生情報の宝庫である。顧客からの問い合わせなどを含むアンケートやコールセンターなどにはクローズドな(非公開)生情報が集まってくる。学会や研究会などでの講演や論文、企業が公開する有価証券報告書、政府や自治体の議会報告や調査資料も専門性のある生情報になるだろう。これらを1次情報系としておく。
こうした生情報にアクセスするための交通整理をしてくれるのが、Google, Yahoo, Naver などの検索サイトである。こうしたサイトは、どんな話題でも検索してくれるので汎用検索サイトと言えるのだが、欠点は検索結果の信頼性にある。そこで信頼性を高める工夫として専門検索サイトが必要になる。学術系では Google Scholar, CiNii Articles, J-STAGE などが知られている。信頼性を裏切って問題になったのが Naver である。これらは2次情報系と言えるだろう。田淵が公開している 論文検索サイト NaCSE, TED 検索サイト selected360 なども2次情報系である。 そこで話を今回の研究会参加者たちの立ち位置にもどす。
本研究会に参加した研究者たちは1次系の生情報を対象とする技術者で、そのうちの一部が2次情報系の構築に関わっている。次に、情報の扱い方としては、社会一般に公開されたものと、企業内や会員など一部グループだけで閲覧する非公開情報とに分けることができる。こうして、(1次、2次)×(公開、非公開)の4つのグループに分かれる。公開と非公開に分けるのは、企業などの団体利益が関わってくることのほかに、著作権の扱いも違ってくるからである。 この4つのグループで発表を分類してみた。もちろん現実は多様なので境界線で区切ってしまうと無理が生じることは承知の上での概念区分なので、ゆるく考えてほしい。 以下のリストの項目は以下の通り
Twitter などへの投稿に不適切なものが混じっていないかを検査することが求められている。現状は人手で行っていて効率と費用面で、自動処理する必要が高まっている。そうしたニーズの基礎研究となる発表。
NLC2018-13 などは論文識別番号なのだが、論文は会員限定の非公開扱いとなっている。参加者以外には非公開なのは残念だ。論文は口頭発表の予稿だが、文献目録がついており、6ページにも及ぶ本格的なもので、非公開はもったいないと思う。ただし発表者は自前で公開可能なので、田淵の論文にはアクセスできるようにしてある。 | |||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||
|
セクション・テーマ: テキスト分析と多分野との境界 表題: テキストアナリティクスと音声解析と認知科学と検索エンジン コード: NLC2018-13 発表者: 田淵龍二 所属: ミント音声教育研究所 日時: 9月6日(木) 午後 13:35-14:00 発表論文: ⇒2018_nlc13.pdf プレゼン原稿: ⇒2018_nlc13_p.pdf 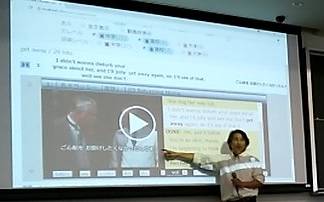 日英対訳コーパスの検索結果を
適応学年で絞り込む操作を説明する田淵
概要: 音声解析に比べて文解析(テキストアナリティクス)は、膨大で良質な資料を手軽に入手できることが特徴である。文解析を俯瞰すると、単語や形態素などを手段としつつ共起や相関を調べたり、目的に応じて絞り込む手法が多く見受けられる。  連続音声の視覚化と呼気段落
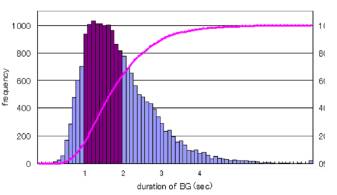 呼気段落長度数の対数正規分布
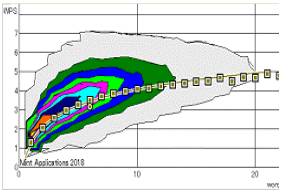 単語数ごと発話速度3D分布と平均値話速曲線
さて、テキスト解析として100年以上前から実用化されてきた技術がある。それがリーダビリティ公式である。日本で著名なフレッシュ・キンケイド公式などを音声解析による認知科学的視点から再評価したところ、作動記憶(ワーキングメモリ)との関連が極めて濃いことがわかってきた。 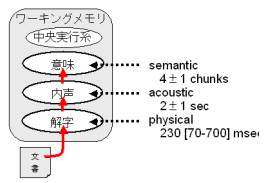 読解プロセスの概要(長期記憶は省略)
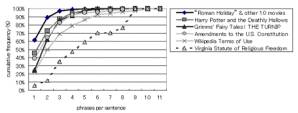 句数で数えた文長ごとの累積
こうした知見を語学(英語)教育における教材選びに応用したアプリを開発した。  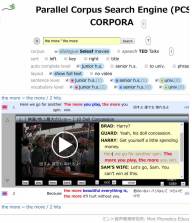 日英対訳コーパス CORPORA
  TED ビデオコーパス selected360
発表では、テキスト読解過程の認知科学的基盤、およびテキストからの音声情報抽出法の説明と、適応学年ごとに学習に最適なテキストや動画を選べる検索エンジンの実演を行い、単語や形態素以外の要素に注目したテキストアナリティクスの多様な一面を紹介した。 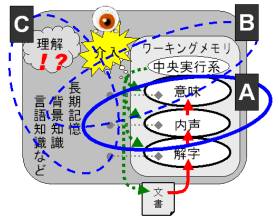 読解プロセスとテキストアナリティクス
| |||||||||||||||||||||||||||||||||||||||
| ..[↑] 7 | |||||||||||||||||||||||||||||||||||||||
|
2018.09.14 田淵龍二 TABUCHI, Ryuji | |||||||||||||||||||||||||||||||||||||||