ミント音声教育研究所
ミント音声教育研究所
ホーム ミント アプリ
ミント アプリ
ケーションズ
ホーム 映画映像シーン検索サイト
映画映像シーン検索サイト
セリーフ 字幕付き動画再生サイト
字幕付き動画再生サイト
トーキーズ ミント名作劇場
ミント名作劇場 日本の昔話
日本の昔話
朗読絵本
「竹取物語」 群馬の昔話
群馬の昔話
朗読絵本
「猿地蔵」」 日本の名作
日本の名作
朗読
芥川龍之介
「トロッコ」 英語朗読絵本
英語朗読絵本
マザーグース Mother Goose 映画
映画
オズの魔法使い
歌「オーバーザレインボー」 映画
映画
カサブランカ
シーン「君の瞳に乾杯」 英語で折り紙 Origami
英語で折り紙 Origami
折鶴 つる crane- ベクターライブラリ
 公開作品一覧
公開作品一覧- 英語作品
 朗読絵本
朗読絵本
ふしぎの国のアリス
第1巻 聞き取りドリル
聞き取りドリル
オバマ大統領 就任演説 聞き取りドリル
聞き取りドリル
オバマ ノーベル平和賞演説- 語学ソフト
 ミングル
ミングル
リーダビリティ計測ソフト ワーズピッカー
ワーズピッカー
英単語拾い2- ゲーム
 朗詠・百人一首
朗詠・百人一首
読み上げ&ゲーム 数独ナンプレゲーム
数独ナンプレゲーム
東海道五十三次
詰独 一人旅 数独ナンプレゲーム
数独ナンプレゲーム
富嶽36景 富士登山
詰独 次の一手- ユーティリティ
 書き起こしソフト
書き起こしソフト
ゆ~ゆ バリュー 書き起こしソフト
書き起こしソフト
ゆ~ゆ ライト 書き起こしソフト
書き起こしソフト
ゆ~ゆ ビジネス 書き起こしソフト
書き起こしソフト
ゆ~ゆ アカデミー
2018/03/12-16 言語処理学会第24回年次大会(NLP2018) | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
━━━━━━━ 時所: 2018年3月12日(月)~16日(金) 会場: 岡山コンベンションセンター(ママカリフォーラム) 主催: 言語処理学会(NLP) ━━━━━━━  会場入り口に張り出された歓迎ポスター(左下)
背景は後楽園と桃太郎の銅像 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
言語処理学会に参加して、その圧倒的な質量に驚かされた。 数字を見るだけですごく人気のある学会だとわかる。
初日と最終日を除く中3日間に、口頭発表が166本、ポスターが156本と過密スケジュールだ。そのため、口頭発表はひとり20分と短かった。しかも、朝9時から夕方7時までぎっしり詰っている。 初日と最終日は少し閑散かと思っていたが、まったく違った。初日の午前中から会場は満杯。しかも若手の企画とあって、学部生から博士課程程度までの若者が大勢詰め掛けていた。ひとつの会場には入りきらないので、主会場と同規模の副会場にモニターを設置するほどであった。 最終日はワークショップと銘打った企画で、私が参加した「形態素解析の今とこれから」には、第一線で解析ツールを開発してきたプログラマ達がずらりと並んで講演した。終わると次は、解析ツールを利用した研究やサービスを提供する企業担当者や若手研究者が加わってシンポへと、朝9時半から夕方の5時すぎまで、熱気があふれっぱなしだった。  プログラムはこちら ⇒http://www.anlp.jp/nlp2018/program.html
 主なスポンサー
発表内容やスポンサーを見るだけで、電子通信技術応用で先端を行く学会であることがわかる。 参加者やスポンサーの増大には主催者も驚いていた。形態素解析やコーパス構築など、専門性の強い学会なので、少数精鋭の地味な学会であったそうだが、近年の人工知能やビッグデータ分析ブームに押されて人気が出てきたことや、若手専門技術者不足に対する業界の動きなどに押されているようであった。こうした動向はスポンサー数の増大に鮮明だ。 2018 56社 **************************** 2017 49社 ************************ 2016 38社 ******************* 2015 30社 *************** 2014 26社 ************* 2013 18社 ********* この5年で3倍増、伸び率にして年25%だ。 スポンサーの多くは、文字言語を媒体としたサービスをしていて、さらに音声言語との融合(音声認識や対話)を牽引しつつある企業であることがわかる。 スポンサーが多いと、いいことも多い。大会会場には休憩所や給水ポイントが4箇所ほど設置され、コーヒーやお茶菓子が常備されていた。疲れた身体と発熱寸前の脳を休ませることができた。
事前申込者が 773人で、一般発表の予稿論文著者が 716人であることから、ほとんどすべての参加者が同時に発表者であることも特徴だろう。何かを創り出すことに携わっている人たちで構成されている学会であることが見て取れた。 このことはポスター発表にも反映されていた。ポスター発表は1回に付き1時間20分の時間帯で4回分も確保されていたが、どのポスターにも人だかりができ、質疑応答が絶えない風だった。 一人でいくつもの発表に名を連ねる研究者も多い。私が構築した予稿集コーパスで調べてみると乾健太郎(東北大/理研AIP)氏は実に22本で共同発表者となっていた。 一人で3本以上の発表に関わっている研究者を数えたところ84人もいた。5本以上でも28人、10本以上は4人。研究熱心な専門家集団であることがよくわかった。 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
以下は筆者が5日間で見聞した企画一覧である。
赤字は筆者の発表
論文賞受賞講演やライトニングトークにはそぞれぞ4名、6名とおられるが、割愛させてもらった。 筆者が5日間で聴講した講演は長短合わせて 35人、一般発表(20分) 34本、ポスター 10本。月曜から金曜まで毎日朝から日暮れまでテーブルについて人の話を聞き続ける生活は、大学はもちろん高校でも経験したことがないほどのハードなものだった。しかし、聴講できた発表は全体の2割に過ぎず、残念だった。 企業など大学以外の発表が多かったように思う。目だった所を数えてみた。 理研 34件 産総研 16件 NTT 15件 Yahoo 8件 国語研 7件 これら5団体で80件、一般発表の4分の1を占めていた。 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
言語処理学会は、転換点を迎えているようであった。 その様子をデータで追って見よう。
ここ15年間の予稿集を検索すると、コーパスに言及する論文は48%、形態素は37%であった。その割合がほとんど変化していないことに注目したい。コーパスと形態素抜きに言語処理は語れないとも言えそうである。 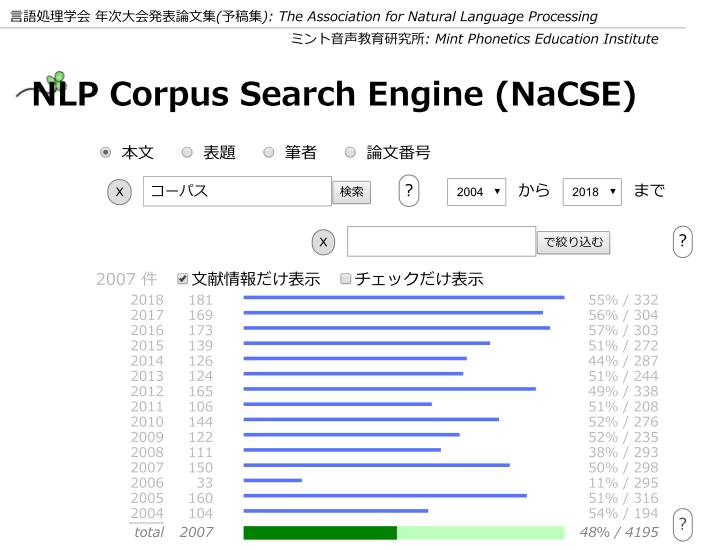 コーパスに言及する発表は毎年半数程度ある
NLP予稿集コーパス NaCSE
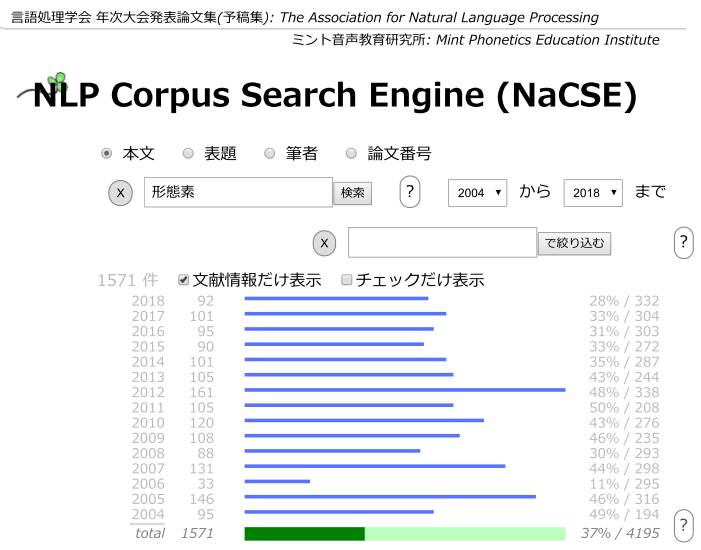 毎年3分の1発表が形態素に言及している
大会5日目のワークショップのテーマが「形態素解析の今とこれから」であり、そこに日本で有数の形態素解析ツールの製作者と利用者が集まったことに見られるとおり、形態素解析はコンピュータによる機械処理が前提である。 ところが、少々意外なことがわかってきた。次のデータを見てみよう。 これは、発表でクラウドソーシングに言及している件数の推移図である。まだ2%程度だが近年確実に増えてきている。  クラウドソーシングが次第に増えてきている
聞きなれない言葉だと思うが、クラウドソーシングはウェブでの仕事を外注することである。具体的中身は現場で異なるが、形態素解析やコーパスで使う語句表現の妥当性や普及度合いを調べるためのアンケートで、対象は一般人である。 次にアノテーションを検索した。 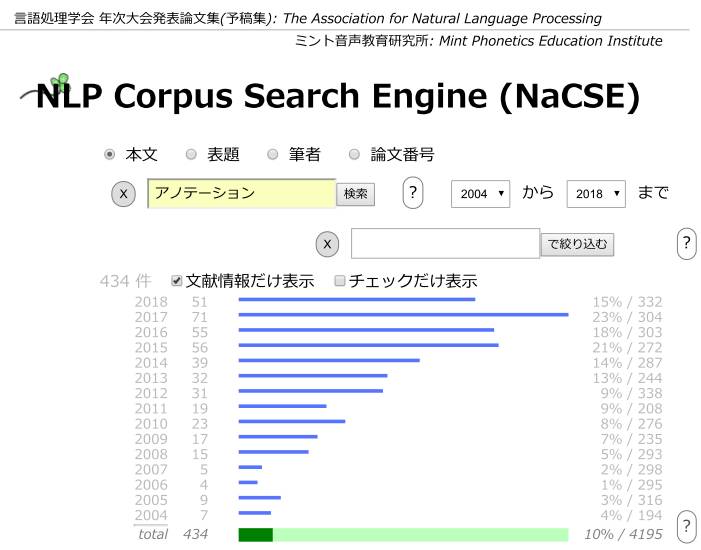 アノテーションはどんどん増えて2割近くになってきた
アノテーションは英語の annotate そのもので、コーパス(辞書)や形態素に言葉の意味を書き添える作業(説明書き)を指している。調べてみると、すべて人手で行っている。 クラウドソーシングやアノテーションから見えてくることは次の2つ。 1. 機械解析処理後の要素(形態素や語句)への意味付与が重要になってきた。 2. 抽出した語句を機械処理するためには、人による意味注釈が欠かせなくなってきた。 論文を読むと、クラウドソーシングやアノテーションへの人的予算が増大しつつあり、負担となってきているようだった。 こうした動向からは、機械処理で発展してきた言語処理分野が「意味」の部分で「人」による人海戦術に頼らざるを得なくなっていることがわかる。 これが第一の転換点(内因=壁)である。 第二の転換点(外因)は、AI(人工頭脳)である。ニューロンネットワークによる深層学習は、形態素解析を必要としなくなる方向で進んでいる。 しかし、実際には人工知能もこれから正念場を迎えることになる。しっかりした成果を出すためには優良なデータを大量に必要とすることから、当面は、分野を限った領域での運用が続くと考えられており、ただちにすべてが代替わりするわけでもないようだ。 このあたりのことは今回の学会でも取り上げられていたが、専門的になるので別の機会に譲ることにする。 ただ、ある大手情報通信会社の担当者と話をすると、東京オリンピックごろまでには外国旅行者と手軽に会話できるシステムが実用化することは確実だとのことだった。この流れが加速すれば、英語教育現場に大きな影響を与えることは間違いないだろう。何でも良いから英語をしていれば言い訳ではないことが一層明白になるからである。 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
田淵龍二(ミント音声教育研究所)の予稿とプレゼン原稿、そして会場での質疑を紹介する。
2018/3/13 15:10-15:30
ハンドアウト: ⇒nlp2018_e2-1h.pdf
2018/3/13 15:50-16:10
ハンドアウト: ⇒nlp2018_e2-3h.pdf
2018/3/14 10:30-10:50
ハンドアウト: ⇒nlp2018_c4-1h.pdf
NLP予稿集コーパス: ⇒http://www.mintap.com/nacse/nacse.html
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| ..[↑] 5 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
2018.03.21 田淵龍二 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||


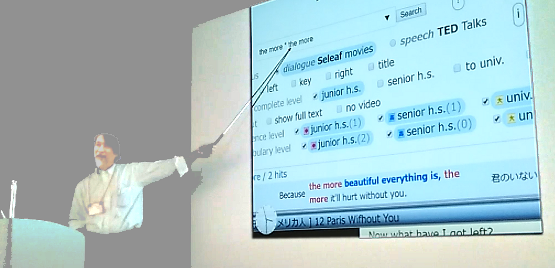




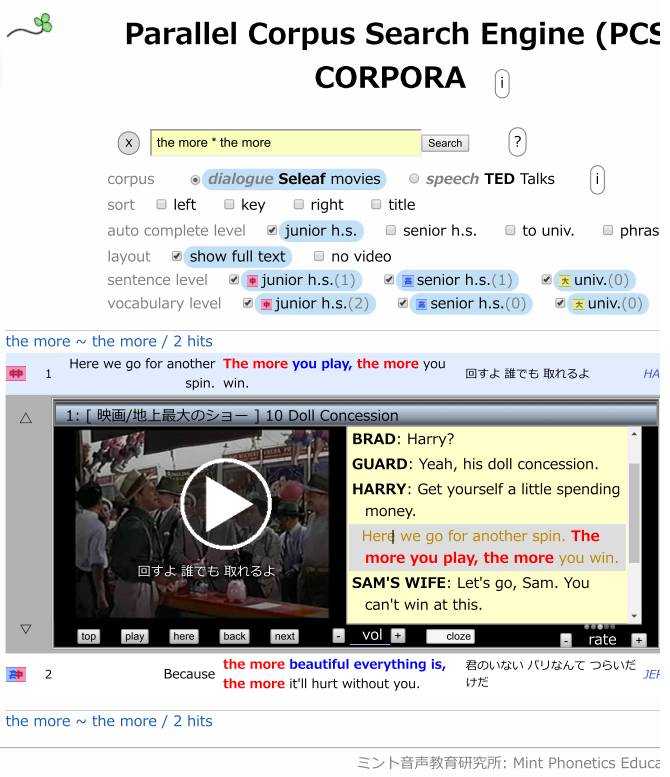 拡大
拡大